Cloud cost management
Purpose: This document provides in-depth information about Verily Workbench activities that incur cloud charges and ways to manage cloud costs when using Workbench.
Cost Management on Verily Workbench
Verily Workbench workspaces are backed by resources from the workspace's cloud provider. This document provides information to help you manage your cloud costs, including:
- Summary list of Workbench activities that DO and do NOT generate cloud charges
- Quick tips for managing common cloud costs
- Detailed explanation of the most common cloud costs for Workbench users
Which activities generate cloud charges?
This table is not exhaustive, as cloud platforms provide many compute and storage services. However, this table provides a look into common Workbench activities.
| Operation | Generates Cloud Charges | Notes |
| Create workspace | No | A cloud project is created, but with no resources. |
| Duplicate workspace | Maybe |
Charges will begin to accrue in your new workspace depending on the cloning instructions of any controlled resources in the source workspace:
|
| Add referenced resource | No | |
| Add a controlled resource bucket | No | An empty bucket generates no charges. |
| Add data to a controlled resource bucket | Yes | Storage charges accrue. |
| Add a controlled resource dataset | No | An empty dataset generates no charges. |
| Add a table to a controlled resource dataset | No | An empty table generates no charges. |
| Add records to a table in a controlled resource dataset | Yes | Storage charges accrue. |
| Create a cloud app | Yes |
Compute resource charges accrue. JupyterLab (Vertex AI Workbench Instance) and JupyterLab (Spark cluster via Dataproc) |
| Stop an app | Yes | Compute charges for your disk accrue. |
| Run a workflow | Yes |
Compute charges for the compute resources for individual task virtual machines accrue. There is no charge for the Cromwell orchestration of a WDL workflow when submitted through the Workbench UI. |
| Cancel a running workflow | Maybe | When a workflow is canceled, no new task virtual machines are created. However, running tasks may continue to run. |
| Copy data from a storage bucket to an app or workflow virtual machine | Maybe |
No, if the bucket and virtual machine are in the same region. Yes, if the bucket and virtual machine are in different regions (Network charges). |
| Download data from a storage bucket to your laptop/workstation | Yes | Data transfer out of Google Cloud from Cloud Storage or cloud virtual machines generates charges. This is usually small (or within Google's Always Free limits) for small data. Large downloads can be significant. Details can be found on the pricing page. |
| Mount a bucket in an app | No | Simply mounting the bucket does not generate any cloud charges. |
| List the contents of a mounted bucket in an app | Not likely | Cloud Storage operation charges are small values based on thousands of operations. This is not common for most interactive analysis. |
| Read from or write data to a mounted bucket in an app | Maybe |
No, if the bucket and virtual machine are in the same region. Yes, if the bucket and virtual machine are in different regions (Network charges). |
| Query data from a BigQuery table | Yes | BigQuery compute charges accrue. |
Quick tips for managing common cloud costs
Building a working knowledge of cloud charges will allow you to save money over the long run. In this section, we give some simple tips that can save you money sooner.
-
Check your cloud charges regularly.
The best way to save money is early detection of charges that will recur. Identifying your largest costs and understanding them often leads to opportunities to reduce or avoid them.
See View your billing reports and cost trends for more information. -
Delete unnecessary files from Cloud Storage.
This applies most to teams with large data, such as those providing large datasets to researchers, or to users running workflows that store intermediate results in Cloud Storage. While Cloud Storage prices are generally low per GB and you only pay for what you use, those charges aggregate every day. Neglecting to delete files you don't need can add up over time. -
Stop your apps when not in use.
For researchers doing interactive analysis, Workbench provides the ability for you to stop your apps when you're not using them. When your app is stopped, you only pay the cost of your disk. You can stop your apps at the end of a work day or over the weekend if you don't need it to keep running. Visit the Workbench home page to see an overview of your running apps and stop them.
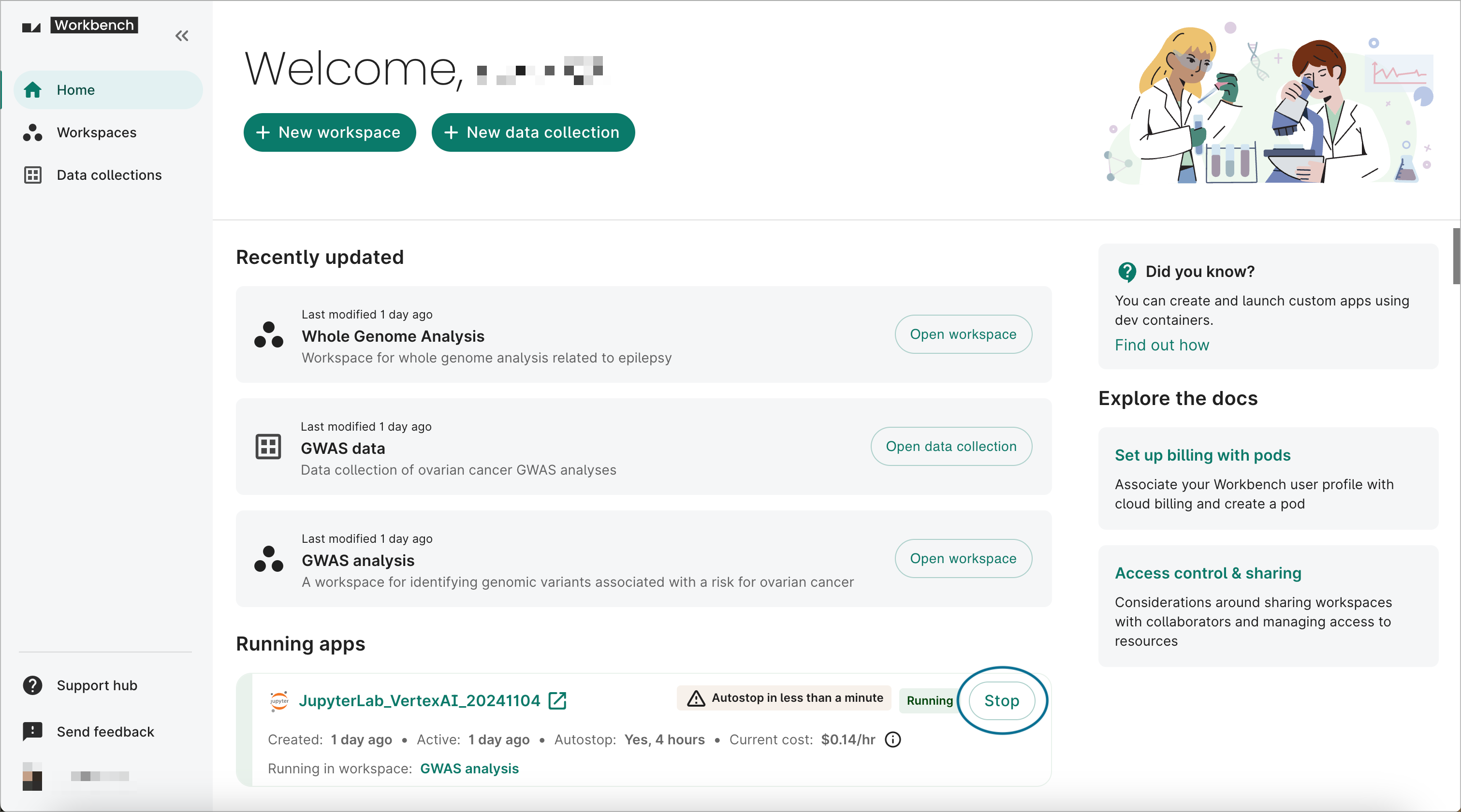
There's also an autostop feature available for apps running on JupyterLab Vertex AI Workbench, R Analysis Environment Compute Engine, Visual Studio Code Compute Engine, or Custom Compute Engine instances. You can have your app automatically stop running after a specified idle time, anywhere from 1 hour to 14 days. This can be configured in the Compute options step when creating an app. You can also enable autostop on an existing app via the Editing dialog.
-
Don't use more compute resources than you need.
Workbench provides access to significant computing power, allowing users to create apps with dozens or hundreds of CPU cores. However, most analysis and time spent writing the code for an analysis requires only a few cores. While you are developing your analysis and doing initial testing, the default app size (2 CPUs, 13 GB of memory) should be sufficient. When you are ready to scale up your analysis, create a new app with more resources and copy your analysis code to the new app. -
Avoid download costs for taking data out of cloud.
Google Cloud does not charge users for accessing data in Cloud Storage as long as that data stays within its storage region. The most common movement of data out of a storage region is when a user downloads data from Google Cloud to their workstation or laptop. For larger data (such as raw omics data), this cost can be significant. As a baseline estimate: copying 10 TiB of data out ofus-central1at a rate of $0.08 / GiB will cost just over $800. -
Use "time to live" on Cloud Storage buckets and BigQuery datasets for throwaway output.
Cloud Storage buckets and BigQuery datasets both support the setup of "autodelete" capabilities. This can be very useful when you are iterating on analysis code or workflows and storing outputs in these services. Rather than needing to remember to delete data later, you can let the cloud remember for you.
To enable a "time to live" on a Cloud Storage bucket in Workbench, use the--auto-deleteflag to wb resource create gcs-bucket. For BigQuery datasets, use the--default-table-lifetime flagto wb resource create bq-dataset.
Cost management on Google Cloud
Google Cloud has hundreds of services with countless features. You can learn much more about cost management on the entire suite of services at cloud.google.com. This section attempts to provide a more focused framework for thinking about cloud charges that is relevant to Workbench users.
There are four broad categories of charges on Google Cloud:
- Storage
- Compute
- Network
- Management
The above are listed in the order that is typically most relevant for Workbench users, with Storage and Compute naturally being the most significant. Each category is discussed below with a few tips for how to think about managing the associated costs.
Storage
Life sciences projects on Workbench are implicitly data driven. This section is particularly relevant to organizations that generate large datasets, but is also important for teams that work with data, producing intermediate and "final" results.
When people talk about Storage on Google Cloud, they are typically referring to two specific services: Cloud Storage (files) and BigQuery (tables).
Note
The term "storage" in cloud parlance is different from "disk storage". So-called "storage services" on cloud are accessible via APIs and tools from many different computing apps concurrently, while "disk storage" is specifically accessible from cloud virtual machines, such as Workbench cloud apps.Cloud Storage
Cloud Storage is a service in which objects are stored in buckets. You can think of it as a place to store files in a structure similar to folders or directories. Cloud Storage buckets exist independent of apps and can be accessed concurrently from apps or from off-cloud machines, such as your laptop or workstation.
Workbench allows users to create and reference Cloud Storage buckets as workspace resources.
The key cost factors for Cloud Storage services:
- Storage
- Networking
Storage costs
The good news for data owners is that while storage is usually the largest cost to consider, these costs tend to be fairly predictable. Cloud platforms publish their storage pricing sheet, and these costs tend to stay consistent over long periods of time. Occasionally prices go down or new options for archive storage emerge, providing opportunities for reducing costs.
As a simple example, Google Cloud publishes its
storage pricing, and for storing data in Google's
us-central1 region, you'll pay $0.02 / GB / month. Google also offers cold storage options for
archiving infrequently accessed data and also now supports the
Autoclass capability that can automatically
classify infrequently accessed data into a colder storage option, saving you money without needing
to manage it yourself.
Networking costs
Google Cloud does not charge users for accessing data in Cloud Storage as long as that data stays
within its storage region. For example, moving data from a bucket in us-central1 to an app in
us-central1 is free. Charges are incurred for moving data out of the storage region.
Users can generate cloud costs by copying data across cloud regions, but the most common movement of data out of a storage region is when a user downloads data from Google Cloud to their workstation or laptop. For small data, this is typically a very small cost. For larger data (such as genomic data), this cost can be significant. The details of Google Cloud's network pricing for moving data out of cloud can be found on the pricing page.
Unfortunately, the exact cost of data download out of cloud can be complicated to calculate, as it
is based on the source location, destination, and amount of data transferred during a billing month.
However, as an example estimate: copying 10 TiB of data out of us-central1 at a rate of $0.08 /
GiB will cost just over $800.
Who pays this data transfer cost? By default, the cost goes to the bucket owner. For data owners granting broad access to researchers, this can present an unacceptable cost risk; users can download the data whenever they like and as often as they like. A solution to this is to enable the Google Cloud Requester Pays feature. With Requester Pays enabled on a bucket, all data transfer costs go to the requester.
Controlling costs
The best ways to save your project money on storage is to:
- Select the least expensive region that satisfies your needs
- Avoid unnecessary storage
- Enable Requester Pays if you grant broad data access
Selecting a region
Google's us-central1 region (our recommended default U.S. region) costs $0.02 / GB / month, while
several other U.S. regions cost $0.023 / GB / month. While this is not a significant difference for
small data over short amounts of time, for 100 TB, the less expensive region will save $300 per
month or $3,600 per year with no extra work or user impact.
In Workbench, you can specify a resource region when you create or edit a workspace, which will by default create new workspace resources in that region.
Avoiding unnecessary storage
A nice feature of Cloud Storage buckets is that you only pay for what you use. When you create a bucket, you don't need to preallocate space like one does with disk storage. Cloud Storage is also generally the least expensive storage option. However, you do pay for what you use and these costs can accrue daily.
A good way to save money year over year is to do an audit of what you are storing. Some options to consider:
- Do I have multiple copies of the data?
- Can the data be reacquired from a central source?
- Can the data be regenerated for less than the cost of storing it?
Over time, for various reasons of convenience, copies of data will be created. A periodic review can identify opportunities to clean up duplicates. You may also realize that you're paying for a private copy of data that can be reacquired at any time from a reliable central source.
Other times, intermediate results files from workflows can be left in Cloud Storage, rather than cleaned up when results are validated. Even with those final results, sometimes it is better to recreate them with an inexpensive workflow instead of paying the cost of storage over many years.
BigQuery
Google BigQuery (BQ) is a managed data warehouse where tables are stored in datasets, including both tabular data and nested data. You can issue SQL queries to filter and retrieve data in BigQuery.
Workbench allows users to create and reference BigQuery datasets as workspace resources.
The key cost factors for BigQuery services:
- Storage
- Compute (aka Query)
- Networking
Storage costs
As with Cloud Storage, BigQuery storage costs tend to be fairly predictable. An even better feature for BigQuery storage is that after 90 days of a table not changing, the storage costs automatically move to a less expensive "long term pricing" rate.
As a simple example, Google Cloud publishes its
storage pricing, and for storing data in
Google's us-central1 region, you'll pay $0.023 / GB / month. After 90 days, that drops
automatically to $0.016 / GB / month.
Compute (aka Query) costs
When running a query in BigQuery, there's a cost for the computation that is computed based on the number of bytes of data that the query looks at. For scanning across small tables, the cost is nominal or non-existent as the first 1 TiB of query data processed per month is free.
For queries over very large tables, query costs (at $6.25 per TiB) can add up very quickly.
Network costs
As with Cloud Storage and all Google Cloud services, network costs can be incurred for moving data out of a region. With BigQuery, these costs tend to be less of an issue as the typical goal of using BigQuery is to do filtering on large data in place in order to return smaller results. If you are generating large results, you'll typically want to write those results to a new table in BigQuery, avoiding networking charges.
Controlling costs
As with controlling costs for Cloud Storage, the first two suggestions for controlling costs for BigQuery are:
- Select the least expensive region that satisfies your needs
- Avoid unnecessary storage
In addition, if you query large tables with BigQuery, you'll want to learn more about ways to minimize the compute costs of queries. BigQuery provides resources for this:
Compute
Google Cloud provides general compute services through Compute Engine virtual machines (VMs). Google additionally provides services that are built on top of these VMs such as Vertex AI Notebook Instances and Cloud Dataproc.
Workbench enables users to access compute services through apps and workflows.
Compute resource costs
For apps and workflow VMs, charges are generated for the allocation of resources. The most expensive compute resources are (in order):
The scale is significant. GPUs are much more expensive than CPUs, which are much more expensive than memory, which is much more expensive than disk storage. Charges for the app are calculated to the second (with a 1-minute minimum). For a detailed understanding of app costs see the VM Instance Pricing documentation. You can also use the Google Cloud Pricing Calculator.
Unlike Cloud Storage, compute resources on Google Cloud are "pay for what you allocate," rather than "pay for what you use." Thus, if you have an app created, running, but sitting idle, you will incur charges for those resources. Similarly, using the CPUs at 100% incurs no additional costs.
Controlling costs
The best way to reduce compute costs is to reduce the resources you have allocated over time. On Workbench, how you approach this will depend on the context:
- JupyterLab (Vertex AI Workbench Instance)
- JupyterLab (Spark cluster via Dataproc)
- Workflows
JupyterLab (Vertex AI Workbench Instance)
On Workbench, the most common researcher use case involves working with analysis-ready data on a JupyterLab app. For this type of usage, cloud costs are quite predictable. Calculating the cost of a single VM is straightforward, and you have some easy ways to avoid unnecessary charges.
Some simple ways to control costs of your JupyterLab app:
- Only use the amount of compute (GPUs, cores, memory) that you need
- Stop your app(s) when not in use
- Delete apps that you don't need
Workbench provides access to significant computing power, allowing users to create apps with up to 96 cores. However, most analysis and time spent writing the code for an analysis requires only a few cores. While you are developing your analysis and doing initial testing, the default app size (2 CPUs, 13 GB of memory) should be sufficient. When you are ready to scale up your analysis, create a new app with more resources and copy your analysis code to the new app.
Workbench also provides the option for you to stop your app when you're not using it. When your app is stopped, you only pay for the cost of your disk. You can stop your apps at the end of a work day or over the weekend if you don't need it to keep running. Visit the Workbench home page to see all of your running apps.
Workbench allows you to create as many apps as you need. However, each such app has a cost. If you don't need an app, copy notebooks and other files off to Cloud Storage and delete the app. You can recreate it when you need it.
For more on app management, see App operations.
JupyterLab (Spark cluster via Dataproc)
Some types of analyses can take advantage of cluster configurations, distributing computation across a set of "worker" compute nodes. Workbench enables this type of computation with Spark clusters provisioned by Cloud Dataproc.
With this type of configuration, it is easy to accrue much more significant charges quickly. Rather than managing the cost of a single node, multiply your costs by the number of worker nodes that you create. For this case, it can be even more essential to make wise choices about the resources you allocate and how long the cluster runs.
All of the advice for single node JupyterLab applies to working with clusters. In addition, Dataproc supports:
If your analysis, such as a Jupyter notebook, has varying levels of computational requirements at different steps, using autoscaling will save on cost as the cluster can grow and shrink on demand, based on the autoscaling policy that you choose.
Spot VMs are much less expensive than regular priced VMs, but may be terminated at any time. If your analysis software is written to be fault tolerant to worker interruption, then spot VMs can help you save on cloud charges.
Workflows
Workbench supports execution of workflows using workflow languages/engines such as WDL/Cromwell, Nextflow, dsub, and Snakemake. With the flexibility and elasticity of the cloud platform, you have computational power at your fingertips to do a tremendous amount of life sciences data processing.
This power also allows you to generate significant cloud charges very quickly. Processing a single genomic sample at ~$6 is not significant, but processing 1,000 or 10,000 samples quickly becomes $6,000 or $60,000. The good news is that these events can be well planned.
When doing a large amount of data processing, it is recommended to:
- Optimize your workflows for running in cloud
- Iterate with "small" data
- Run a batch of representative samples
- View the cloud costs to estimate total costs before running at scale
Steps 2-4 are primarily about being methodical and not rushing to run your workflow at scale.
Optimizing workflows for cloud
To save on compute costs, approach optimization in the following order:
- Use preemptible VMs
- Reduce the number of GPUs or CPUs (they are the most expensive resources)
- Reduce the amount of memory
- Reduce the amount of disk used
Workflows engines on Google Cloud can use "preemptible VMs" (very low-cost VMs which may get terminated prior to task completion). Their use can significantly reduce the cost of running workflows.
Some additional details to know about using preemptible VMs
- Smaller VMs are less likely to be preempted than large VMs
- Preemption rates are typically lower during off-hours (nights and weekends)
- Preemptions tend to happen early in a VM's lifetime
To minimize lost work, Compute Engine tries to avoid preempting instances "late" in their 24-hour maximum allocation time. So while running on a preemptible VM and getting preempted adds cost overhead (cutting into your savings), such preemptions tend to happen early and the additional cost is modest.
For more information, see these preemptible VM best practices.
Saving on associated storage costs
Cloud-based workflow runners typically use Cloud Storage for intermediate results from different task VMs and different execution stages. If not cleaned up, these intermediate files have the potential to add unexpected large storage costs. When you have validated your final outputs, be sure to delete the intermediate files.
Network
Data transfer out costs
As noted separately in the Storage and Compute sections above, Google Cloud does not charge users for accessing data in Cloud Storage as long as that data stays within its storage region. Movement of small amounts of data between cloud regions or out of cloud will be small or may even fall into Google's monthly free tier.
Controlling costs
With larger amounts of data, it can be very costly to move data between cloud regions or out of cloud. Workbench will help with this by creating resources such as buckets and apps in your workspace's default region. But before transferring large amounts of data (or small amounts repeatedly) between a bucket and a cloud virtual machine, it is a good practice to ensure you know what region those cloud resources are in.
Tip
What region is my bucket in?
On your app, you can use gsutil to get the metadata for a bucket with the command:
gsutil ls -Lb gs://<bucket-name>
For example:
$ gsutil ls -Lb gs://test-bucket-for-notebooks-terra-glossy-spinach-5323/ | grep Location
Location type: region
Location constraint: US-CENTRAL1
What region is my app in?
On your app, you can use curl to query the instance metadata for the zone (a specific data center
within a region) with the command:
curl -s "http://metadata.google.internal/computeMetadata/v1/instance/zone" -H "Metadata-Flavor: Google" | \
sed -e 's#.*/##' -e 's#-[^-]\+$#\n#'
For example:
$ curl -s "http://metadata.google.internal/computeMetadata/v1/instance/zone" -H "Metadata-Flavor: Google" \
| sed -e 's#.*/##' -e 's#-[^-]\+$#\n#'
us-central1
Management
Vertex AI Workbench Instance management fees
Workbench apps include the option of JupyterLab on a Vertex AI Workbench Instance. These instances use so-called "user-managed notebooks." Google Cloud adds a fixed cost per GPU or CPU core as described on the pricing page. Be aware of this additional overhead when allocating app resources.
Dataproc management fees
Workbench apps include the option of JupyterLab on a Dataproc cluster. Google Cloud adds a fixed cost per CPU core as described on the pricing page. Be aware of this additional overhead when allocating app resources.
Autoclass management fees
Google Cloud's new Autoclass feature for Cloud Storage is designed to help you save money by automatically moving your infrequently used data to a less expensive storage class. You can use Autoclass for your referenced resource buckets. Autoclass includes management and enablement fees which should be taken into account before enabling it.
Last Modified: 27 November 2024