Workflows overview
Categories:
Purpose: This document provides a high-level understanding of workflows in Verily Workbench.
What are workflows and what capabilities do they provide?
A workflow streamlines multi-stage data processing by executing tasks autonomously, in accordance with your specified inputs. Workflows can confer many advantages, especially for large datasets and outputs, such as increasing efficiency and reproducibility while reducing bottlenecks. Running instances of workflows are often called "jobs," with each job being split into a series of tasks for the workflow to run through.
A computational workflow is a sequence of computational steps that are used to process data. It's a formalized description of how data is input, how it flows between steps, and how it is output. Computational workflows are widely used in data analysis, scientific computing, and engineering.
Using workflows for your analyses offers the following advantages over running computational steps individually:
- Reproducibility: Using workflows helps ensure that the results of an analysis can be reproduced by others. This is important for scientific research, where it is essential that the results of an experiment can be verified by other researchers.
- Portability and sharing: If you use a widely-supported workflow language, you can run the same workflow on different platforms, which gives you the freedom to choose the platform you want to use. It also enables you to share your workflows with others who use different platforms, and to use workflows developed by others in the community.
- Scalability: Workflows enable you to handle large datasets by automating execution and reducing the possibility of error.
Verily Workbench provides built-in support for running and monitoring WDL-based workflows via the Cromwell workflow engine. Right within the UI, you can add workflows, run them with a set of inputs, and monitor their execution. Alternatively, you can use dsub or Nextflow to run your workflows in Workbench.
How workflows execute on Workbench
Executing workflows on Workbench involves bringing together a workflow definition and supporting code, along with configuration and data for processing as represented in this overview image:
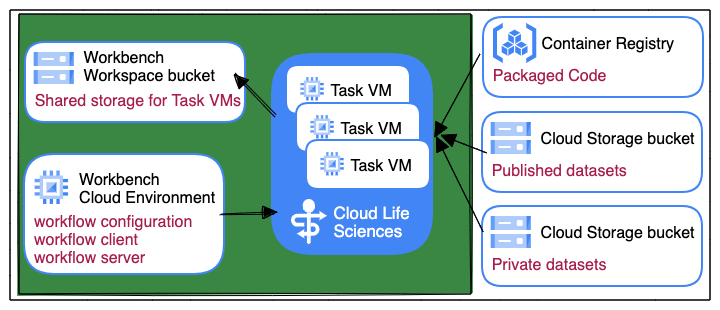
This section describes each of these components in more detail.
Orchestration and task execution
The image below highlights key elements of a single workflow job executing on Workbench:
- Workflow graph
- Workflow orchestration
- Task execution
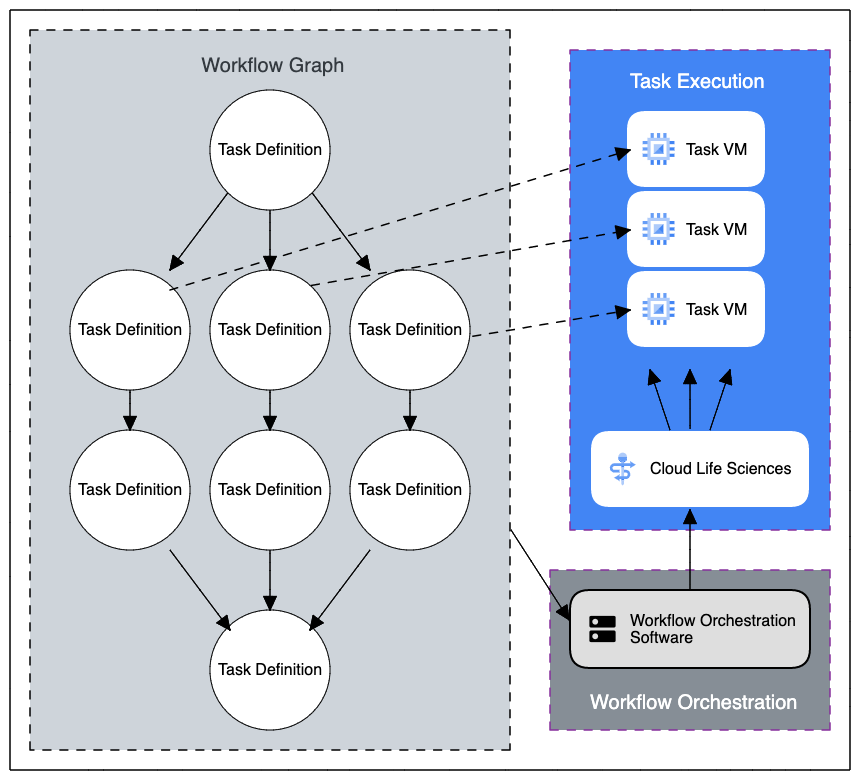
The left-hand side shows an example of a moderately advanced workflow, which includes multiple tasks that must be executed in a particular order (with some tasks executing in parallel). Workflows can be orchestrated by sophisticated workflow engines such as Cromwell or Nextflow. For less complex (especially single-task) workflows, you can write a script that uses dsub to launch those tasks.
To scale execution on Workbench, orchestration and task execution occur on different machines. The Cloud Life Sciences API is used by dsub, Cromwell, and Nextflow to schedule and monitor task-specific VMs.
Workflow credentials
Each of the workflow engines documented here use the Google Cloud Life Sciences API to run task VMs in your Workbench workspace. There are two key credentials to be aware of:
- Privileges to call the Life Sciences API
- Credentials used on each task VM
When you submit workflow execution from your cloud app, you’ll be calling the Life Sciences API with your workspace service account credentials. Each task VM executes with workspace service account credentials.
Workflow client and server software
dsub, Cromwell, and Nextflow each provide client software to submit and monitor workflows.
Cromwell and Nextflow provide server software that you can run on your Workbench app to scale up execution and management of large numbers of workflows.
The software for dsub, Cromwell, and Nextflow is pre-installed on Workbench apps.
Workflow code
Whether it’s a community-published workflow that you discover in Dockstore, a workflow shared within your organization, or your own private workflow, permanent storage of your workflow code will typically be in source control. To run the workflow, you’ll first need to copy the workflow code from its storage location to your Workbench app such that it's available to the workflow client.
Workbench supports integrated access to GitHub. Adding a GitHub repo to your workspace will automatically sync that repo to any app that you create in that workspace. This makes it easy to launch workflows in that workspace, update workflow code, or commit input parameters and logs to source control.
Task code
Code for each workflow task is typically embedded in the workflow description, and those commands run inside of a Docker container. The Docker images for your workflows can come from any Docker registry accessible to the task VM. This can include repositories such as Docker Hub, Quay.io, GitHub, Google Container Registry, or Artifact Registry.
Workbench supports authenticated access to Google Container Registry and Artifact Registry using your workspace service account credentials.
Workflow configuration
When you submit workflows from your Workbench app, you’ll need to provide a list of parameters for each workflow, including input paths and output paths (discussed further below).
Each workflow engine includes a way to provide lists of inputs. For example, you can submit a batch of genomic samples to be processed. These lists of input parameters will be stored on your Workbench app.
Workflow inputs
While you can create workflows that read from database tables and other sources, the native preferences for dsub, Nextflow, and Cromwell are to use files as inputs. On Workbench, those files are stored in Cloud Storage buckets.
Depending on the workflows that you run, you'll often use some combination of files from
public datasets, shared
access datasets (where you've been given access), and private datasets (that you own). Each of the
workflow engines have native support for files using cloud-native storage path URLs (such as
gs://bucket/path/file), localizing those files from the storage bucket to a task VM's local disk,
including built-in support for
Requester Pays buckets.
For reading from any shared access or private cloud buckets, your workspace service account will need to have been granted Read access. Your workspace service account will have access to each bucket in your Workbench workspace.
Workflow outputs
You can create workflows that write to database tables and other destinations;, however, the "native" capabilities for dsub, Nextflow, and Cromwell use files as outputs, and on Workbench those files are stored in Cloud Storage buckets.
Typically, you will write intermediate and final outputs to a bucket in your workspace. Should you
wish to have your workflows write outputs to a bucket outside of your workspace, you will need to
have Write access granted to your workspace service account.
Workflow options in Workbench
As mentioned above, Workbench supports workflows on Cromwell, dsub, and Nextflow. See Workflows in Verily Workbench: Cromwell, dsub, and Nextflow to determine which one best fits your needs.
Last Modified: 25 November 2024